
Il Problema: l’Alert che Scatta Sempre Tardi
Chi ha scritto anche solo una regola di alerting in Prometheus ha probabilmente già incontrato qualcosa di molto simile a questa:
node_filesystem_avail_bytes / node_filesystem_size_bytes < 0.1È la regola che finisce copiata dal primo tutorial trovato, e che popola almeno metà dei file alerts.yml in giro per il mondo. Il problema di questa regola non è la sintassi, né il valore della soglia: il problema è la domanda a cui sta rispondendo. La query segnala che il disco è pieno adesso, in questo momento preciso. Quando scatta, l’occupazione è già al 90%, i log stanno probabilmente fallendo a scrivere su disco e qualche servizio sta già restituendo ENOSPC ai suoi client.
Una domanda diversa, e molto più utile dal punto di vista operativo, sarebbe “il disco si riempirà entro una finestra temporale in cui è ancora possibile intervenire senza svegliare nessuno nel cuore della notte?”. È una domanda diversa, e richiede un alert diverso: non un aggiustamento di soglia, ma una query che ragiona sul trend invece che sullo stato.
Questa distinzione non è una curiosità accademica: ha radici teoriche precise in due framework che chiunque si occupi di observability ha sentito nominare, USE e Golden Signals. Nel resto dell’articolo si vede da dove arriva la differenza, come tradurla in regole Prometheus concrete con predict_linear, e soprattutto quando gli alert predittivi sono l’idea giusta e quando invece sono un errore.
USE vs Golden Signals: Due Definizioni di Saturation
Partiamo dalle fonti primarie, perché qui i dettagli contano. Il metodo USE è stato formalizzato da Brendan Gregg nel 2012, partendo dal suo lavoro di performance engineering su Solaris prima e Linux poi. L’acronimo sta per Utilization, Saturation, Errors, ed è pensato come checklist operativa per diagnosticare problemi di performance a livello di risorsa hardware: CPU, memoria, disco, rete.
I Four Golden Signals arrivano qualche anno dopo, codificati nel Google SRE Book del 2016, nel capitolo 6 “Monitoring Distributed Systems”. L’approccio è diverso: invece di partire dalla risorsa fisica, parte dal servizio visto dall’esterno. Latency, traffic, errors, saturation: le quattro dimensioni su cui un SRE dovrebbe costruire il proprio monitoring di base.
Entrambi i framework usano la parola “saturation”, ma la definiscono in modo sottilmente diverso. Gregg è esplicito:
“the degree to which the resource has extra work which it can’t service, often queued”
Fonte: brendangregg.com/usemethod.html
La saturation USE è, letteralmente, la coda di lavoro che la risorsa non riesce a smaltire adesso. È una misura istantanea: lunghezza della run queue della CPU, pagine in swap, pacchetti in attesa nel buffer di rete. Il libro SRE, nel capitolo sui Golden Signals, usa invece una definizione che include esplicitamente la dimensione temporale futura:
“saturation is also concerned with predictions of impending saturation, such as ‘It looks like your database will fill its hard drive in 4 hours.’”
Fonte: sre.google/sre-book/monitoring-distributed-systems/
Questa frase compare letteralmente nel libro, in un paragrafo che discute come strumentare la saturation, quindi non si tratta di una lettura creativa del testo. Il punto chiave, che troppo spesso passa inosservato nelle discussioni su alerting, è che USE misura saturation come stato corrente, mentre i Golden Signals la definiscono includendo le predizioni. Sono due framework compatibili ma con focus diversi, e questa differenza si traduce direttamente nel tipo di alert che ciascuno abilita.
| USE (Brendan Gregg, 2012) | Golden Signals (Google SRE, 2016) | |
|---|---|---|
| Cosa misura | Coda di lavoro in attesa adesso | Quanto è “piena” la risorsa, incluse predizioni |
| Quando scatta | Quando il problema sta degradando il servizio | Quando il trend lo prevede entro un orizzonte |
| Azione abilitata | Mitigazione reattiva | Pianificazione, scaling preventivo |
Tenere a mente questa distinzione rende molto più facile rispondere alla domanda “che tipo di alert mi serve qui?”, perché costringe a esplicitare se l’oggetto del monitoraggio è uno stato o un trend.
Symptom-based vs Cause-based: Quando Ricevi la Pagina
C’è un altro asse su cui ragionare, ortogonale al precedente, e che la letteratura SRE identifica come symptom-based vs cause-based. Un alert reattivo è tipicamente symptom-based: scatta quando il problema si sta manifestando, è tardivo ma molto preciso, perché non sta prevedendo nulla ma osservando. Un alert predittivo è cause-based con un orizzonte temporale: cerca di anticipare il sintomo osservando un indicatore di causa che tende verso un limite noto. Proattivo ma per definizione stimato, quindi esposto a falsi positivi quando il modello sottostante si rompe. Nessuno dei due approcci è universalmente migliore dell’altro, e trattarli come alternative è un errore comune.
Per fissare la differenza, si consideri lo stesso sistema con due alert diversi sulla stessa metrica, l’heap usato di una JVM in produzione. Il primo è un classico alert reattivo: “se l’heap supera il 90% per più di cinque minuti, pagina l’oncall”. Scatta alle 3 di notte, perché la metrica ha effettivamente toccato quella soglia. L’heap è al 92%, la JVM è entrata in una GC storm, le latenze p99 sono già degradate di un ordine di grandezza e qualche endpoint sta restituendo timeout. L’oncall si sveglia, diagnostica, fa un restart di emergenza e mitiga sotto pressione. L’alert ha fatto il suo lavoro e il servizio è salvo, ma il costo operativo è altissimo.
Il secondo alert è predittivo, sulla stessa metrica: usa predict_linear con una finestra di sei ore di storia e un orizzonte di due ore. Scatta alle 17:00, con l’heap ancora al 60%, ma il trend di crescita dice che entro due ore si toccherà il limite massimo. L’oncall in turno diurno apre un ticket, coordina un restart pianificato durante la maintenance window serale prevista, nessuno si sveglia di notte e nessun utente vede timeout.
Entrambi gli alert hanno senso e rispondono a bisogni operativi diversi: il predittivo non sostituisce il reattivo, sono complementari. Il reattivo è la rete di sicurezza quando la predizione fallisce, ad esempio quando l’heap cresce improvvisamente in modo non lineare per un cambio di carico. Capire quale alert risponde a quale domanda è il punto di tutto l’articolo, e senza questa chiarezza si finisce inevitabilmente per scrivere regole che scattano troppo spesso, troppo tardi, o entrambe le cose insieme.
predict_linear: Anatomia della Funzione
Prima di passare agli esempi, vale la pena esaminare la funzione al centro di tutto. La firma in PromQL è questa:
predict_linear(v range-vector, t scalar)Cosa fa, in una riga: calcola una regressione lineare semplice sulla finestra v passata come range-vector e proietta il risultato t secondi nel futuro, restituendo il valore stimato della metrica al tempo now + t. Un esempio concreto rende tutto più chiaro:
# Stima il valore di una gauge fra 4 ore basandosi sull'ultima ora di dati
predict_linear(some_metric[1h], 4 * 3600)Cosa predict_linear assume: che la crescita nella finestra osservata sia sostanzialmente lineare. Cosa invece non fa: non modella stagionalità, non riconosce cambi di regime, non si accorge di curve esponenziali o di salti a scalini. È un modello volutamente semplice, e questa semplicità è sia il suo punto di forza (prevedibile, veloce, facile da ragionare) sia il suo limite.
Vale la pena confrontarla con due funzioni vicine che a volte fanno lo stesso lavoro meglio:
rate(counter[1m]): variazione media al secondo di un counter monotono crescente, usato per calcolare throughput ed error ratederiv(gauge[5m]): pendenza della retta di regressione lineare calcolata su una gauge, espressa come variazione per secondopredict_linear(gauge[1h], t): estrapolazione del valore stimato atsecondi nel futuro, basata sulla stessa regressione
Il punto chiave da ricordare è che predict_linear(v, t) equivale concettualmente a deriv(v) * t + valore_corrente: niente di più sofisticato di una retta estrapolata in avanti. Quando l’assunzione lineare regge (è il caso di parecchie risorse reali, come la crescita dell’heap in una JVM sana o l’occupazione di un disco di log) la funzione fa esattamente quello che serve. Quando si rompe, servono strategie diverse (si veda la sezione 7).
Cinque Esempi PromQL Reali
Il caso del disco che si riempie è l’esempio da manuale, ma rischia di dare l’impressione che predict_linear sia un martello monouso. In realtà lo spettro di casi reali è molto più ampio, e include scenari in cui la funzione è perfetta, scenari in cui è la scelta sbagliata, e scenari in cui la predizione è già incapsulata nella metrica stessa. Seguono cinque esempi che coprono questo spettro, dal più reattivo al più predittivo.
5.1 Certificato TLS in Scadenza
(probe_ssl_earliest_cert_expiry - time()) / 86400 < 7Questo è il caso predittivo per eccellenza, ma vale la pena notare una cosa: non c’è predict_linear. Il motivo è che la metrica probe_ssl_earliest_cert_expiry, esposta dal blackbox_exporter, è già definita come “timestamp Unix della scadenza più vicina”. Sottraendo time() (l’istante corrente) e dividendo per 86400 (i secondi in un giorno) si ottengono i giorni rimanenti prima della scadenza. La forma più pulita di alert predittivo non richiede estrapolazione: è semplice aritmetica tra due timestamp. Il “predittivo” in questo caso vive nella metrica stessa, non nella query, ed è tipicamente il pattern da preferire quando la metrica lo consente: meno assunzioni, meno modelli, meno modi di sbagliare.
5.2 Memory Leak Progressivo nella JVM
predict_linear(jvm_memory_used_bytes{area="heap"}[6h], 2 * 3600)
> on(instance) jvm_memory_max_bytes{area="heap"}I nomi jvm_memory_used_bytes e jvm_memory_max_bytes con label area="heap" sono quelli esposti da Micrometer (Spring Boot Actuator) ed equivalenti, ed è il pattern più comune in produzione su stack JVM moderni. La finestra è lunga (sei ore di storia) deliberatamente, per filtrare il rumore dei cicli di garbage collection che fanno “respirare” l’heap su e giù con oscillazioni anche notevoli. Una finestra corta verrebbe dominata da quelle oscillazioni e produrrebbe una pendenza molto rumorosa; sei ore catturano il trend di fondo, che è quello rilevante per individuare un leak progressivo. La proiezione a due ore dà tempo sufficiente a un oncall in turno diurno di aprire un ticket, coordinare un restart pianificato e intervenire senza drammi prima che la JVM finisca in OOM. La join on(instance) è critica: accoppia ogni jvm_memory_used_bytes con il jvm_memory_max_bytes della stessa istanza, senza la quale Prometheus rifiuta l’operazione perché i due vettori hanno label set diversi. Nota importante: questa è la versione “production realistica”. Il demo di accompagnamento nel repository usa una metrica custom jvm_heap_used_bytes (senza label area) e una finestra molto più corta per essere osservabile in pochi minuti anziché ore.
5.3 Quota API Mensile
# Pseudocodice: predict_linear su finestra 24h proiettata fino a fine mese
predict_linear(api_calls_total[24h], 7 * 86400) > monthly_quotaCaso classico per integrazioni con servizi tipo Stripe, Twilio, OpenAI, o qualsiasi provider che fattura in base a un budget mensile di chiamate. L’ultima cosa che si vuole è scoprire alle 23:00 del 28 del mese di aver esaurito il budget, con il servizio che smette di funzionare fino al primo del mese successivo. Avvertenza tecnica importante: PromQL non ha una funzione days_until_month_end() built-in, quindi la query mostrata sopra è una semplificazione didattica. Per fare la cosa giusta in produzione ci sono due opzioni:
- una recording rule che calcola
days_to_month_endusandomonth(),day_of_month()e aritmetica giorno per giorno, poi riusata come scalar nella query di alert - una metrica esposta dall’applicazione stessa (ad esempio
billing_period_seconds_remaining) che incapsula la logica del periodo di fatturazione lato producer, spostando il problema fuori da Prometheus
L’esempio qui sopra usa un orizzonte fisso a sette giorni per semplicità, ma la query reale in produzione dipende dalla recording rule o dalla metrica custom scelta per esporre il periodo residuo.
5.4 Kafka Consumer Lag in Crescita Sostenuta
deriv(kafka_consumergroup_lag[15m]) > 1000 / 60Qui deriv() fa un lavoro migliore di predict_linear, ed è istruttivo capire perché. L’informazione rilevante per un consumer Kafka non è il valore assoluto del lag fra due ore, ma il tasso di crescita sostenuto: se il lag cresce costantemente di mille messaggi al minuto (circa sedici al secondo), c’è un problema strutturale di capacità del consumer anche partendo da numeri bassi, e il problema peggiorerà finché nessuno interviene. La regola scatta quando la pendenza della retta di regressione su quindici minuti supera sedici messaggi al secondo, sostenuta nel tempo. La predizione qui è implicita: un trend è già una predizione, semplicemente espressa come pendenza invece che come valore estrapolato.
5.5 Connection Pool Saturo (Contro-esempio Reattivo)
(db_connection_pool_active / db_connection_pool_max) > 0.9Nessuna predizione, nessuna funzione predict_linear, nessun trend: solo una soglia statica sullo stato corrente. Il motivo è operativo: un connection pool si satura in secondi, non in ore, e l’unico alert utile è “sta succedendo adesso, intervenire subito”. Non c’è una finestra di intervento da anticipare: quando il rate di richieste salta improvvisamente, il pool si riempie più veloce di qualsiasi predict_linear[5m] con un orizzonte sensato, e al momento in cui la predizione scatterebbe il problema è già in corso da minuti. Questo è un contro-esempio deliberato: non tutto va reso predittivo. L’alert giusto è quello che corrisponde alla scala temporale del problema, e per problemi che esplodono in secondi la scala temporale giusta è il presente.
Regola di selezione:
predict_linearè adatto quando esiste una soglia assoluta chiara (limite heap, quota mensile, scadenza certificato) e un orizzonte temporale di ore o giorni in cui agire.derivè la scelta quando l’informazione rilevante è il tasso di cambiamento indipendentemente dal valore assoluto. Una soglia statica reattiva serve quando la risorsa si satura in secondi e non c’è finestra di intervento da anticipare.
Vediamolo in Azione: Demo Prometheus + Grafana
La teoria fin qui è stata necessaria, ma vedere il comportamento dei due alert sulla stessa metrica in tempo reale chiarisce la differenza molto più velocemente. Il repository collegato contiene un demo Docker Compose minimale che simula esattamente lo scenario descritto nella sezione 3: una JVM con un memory leak lineare, e gli stessi due alert (uno reattivo, uno predittivo) che competono sulla stessa metrica. L’obiettivo è rendere concreto il gap di lead time discusso finora solo in formule.
Lo stack è composto da tre container: un fake exporter Python che usa prometheus_client per esporre una gauge jvm_heap_used_bytes che cresce linearmente a 2 MB/s da 100 MB verso 1 GB, una istanza di Prometheus con entrambe le regole alert caricate, e una Grafana con la dashboard pre-provisionata. Niente registrazione, niente login: tre comandi avviano l’intero stack. Il fake exporter è volutamente banale perché l’interesse non è simulare una JVM realistica ma osservare come le regole PromQL reagiscono a una curva lineare pulita.
git clone https://github.com/monte97/saturation-predittiva-demo
cd saturation-predittiva-demo
docker compose up --buildDopo qualche secondo di build, i tre servizi sono live. Grafana risponde su http://localhost:3000, ingresso anonimo come admin, dashboard Saturation: Predictive vs Reactive. La timeline qui sotto descrive cosa succede in tempo reale.
t=0:00 heap = 100 MB | nessun alert
t=2:00 heap = 340 MB | predittiva inizia a valutare (serve 2min di storia)
t=3:30 heap = 520 MB | PREDITTIVA firing: proiezione a 5min sfonda 1GB
t=6:50 heap = 920 MB | REATTIVA firing: heap > 90%
t=7:40 heap = 1 GB | saturazione realeLa cosa interessante è il gap fra la riga t=3:30 e la riga t=6:50. Sono circa tre minuti di lead time che l’alert predittivo offre in uno scenario didattico compresso. In un sistema reale, dove il leak è dell’ordine di decine di MB/ora invece che 2 MB/sec, lo stesso identico pattern darebbe ore o giorni di anticipo. Il rapporto tra finestra di osservazione e velocità del leak determina il moltiplicatore.
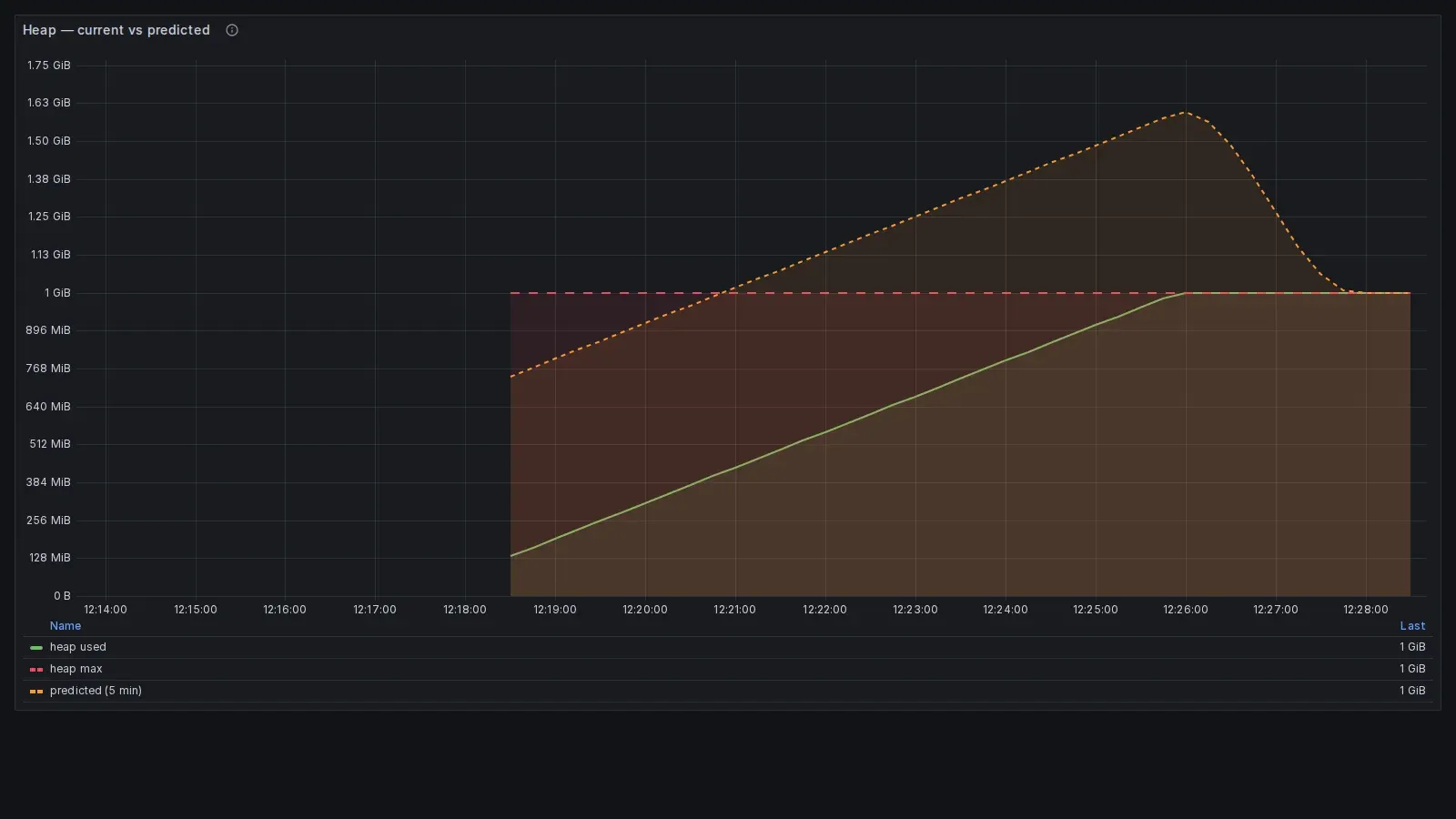
La linea verde è l’heap effettivamente usato dalla JVM simulata, la linea rossa tratteggiata è il limite massimo (1 GiB), la linea arancione tratteggiata è la proiezione
predict_lineara 5 minuti. La linea arancione incrocia la rossa intorno alle 12:20, mentre la verde la raggiunge solo verso le 12:26: quei sei minuti di anticipo sono esattamente il lead time dell’alert predittivo.
Il primo pannello mostra le metriche grezze, ma il secondo è ancora più diretto: due step chart che indicano quando ciascun alert è in stato firing. Qui il gap temporale diventa visivamente impossibile da ignorare, e permette di leggere il vantaggio operativo senza dover interpretare la geometria delle curve.
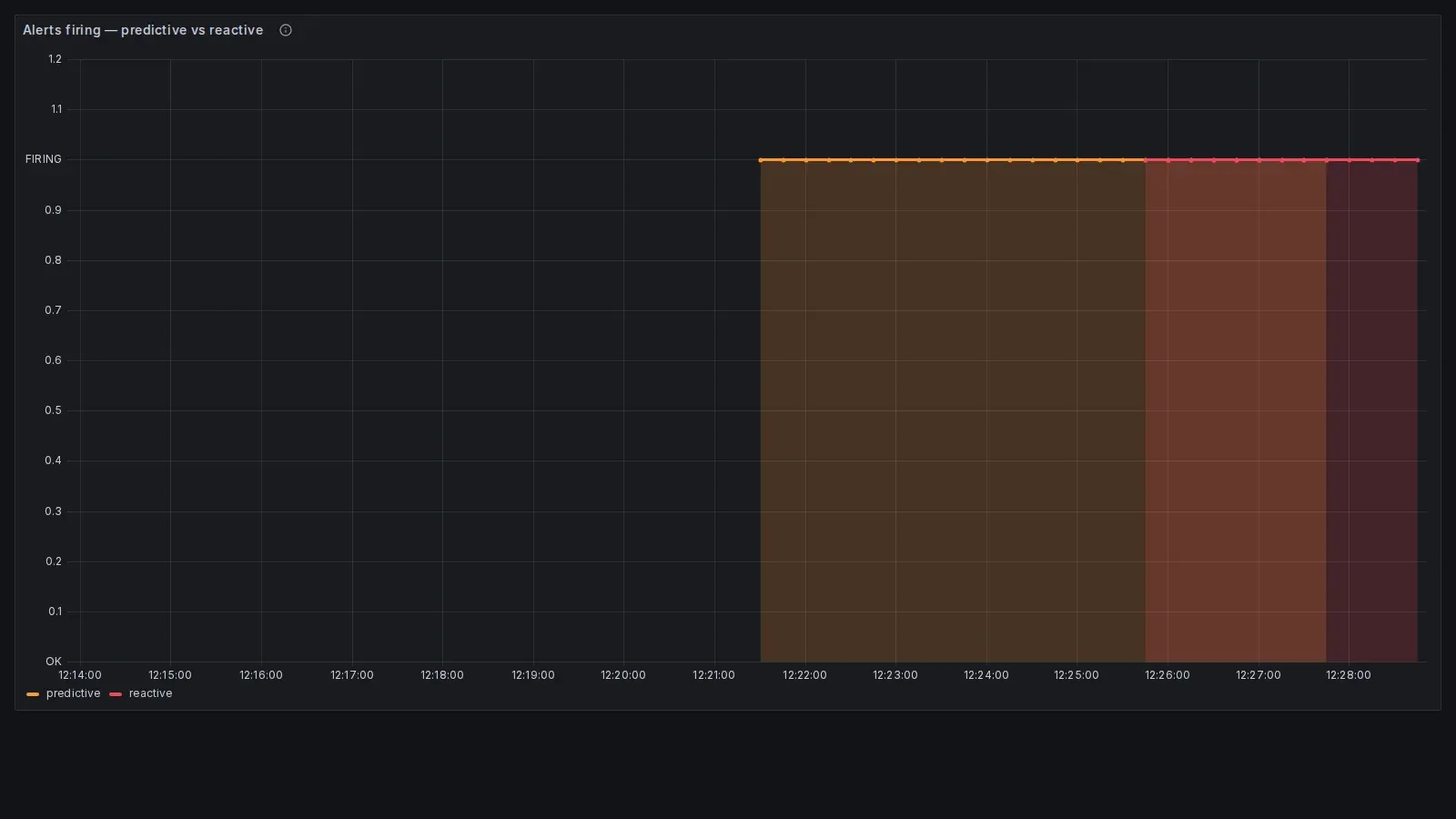
L’alert predittivo (arancione) entra in
firingintorno alle 12:21:30, l’alert reattivo (rosa) intorno alle 12:25:30. Quattro minuti netti di anticipo nel demo compresso. In produzione, con un leak di 50 MB/ora invece di 2 MB/sec, lo stesso pattern darebbe oltre quattro ore di anticipo: abbastanza per un restart pianificato durante il giorno invece di una pagina notturna.
Il docker-compose.yml espone tre variabili d’ambiente (START_HEAP_MB, MAX_HEAP_MB, GROWTH_MB_PER_SEC) che permettono di rallentare il leak per simulare scenari più realistici, o di accelerarlo per osservare il pattern in tempi brevi. Le regole alert vivono in prometheus/alerts.yml e non richiedono rebuild: basta riavviare il container prometheus per ricaricarle.
Le Trappole della Saturation Predittiva
predict_linear è uno strumento potente, ma ha quattro modalità di fallimento tipiche in produzione. Vale la pena conoscerle prima di mettere una regola predittiva in pager, perché ciascuna di queste trappole si manifesta come rumore operativo difficile da diagnosticare a posteriori.
Crescita non lineare
La funzione assume, per definizione, una retta. Ci sono almeno tre famiglie di casi reali in cui questa assunzione si rompe in modo sistematico. La prima è il memory leak che peggiora esponenzialmente, tipicamente un loop di riferimenti che accumula oggetti sempre più velocemente man mano che la struttura cresce. La seconda sono le allocazioni che rallentano avvicinandosi al limite, perché la pressione del garbage collector aumenta e ogni nuova allocation costa progressivamente di più. La terza è la crescita a scalini, come un cronjob che aggiunge cento megabyte ogni notte e resta piatto per le restanti ventitré ore del giorno.
In tutti questi casi la regressione lineare sbaglia: in difetto se la curva è convessa, in eccesso se è concava. Il sintomo tipico è un alert che scatta troppo presto e diventa rumore ignorato, oppure troppo tardi e perde utilità come anticipo.
Finestra troppo corta
Una query come predict_linear(metric[5m], 4 * 3600) reagisce in modo pesante al rumore della finestra. Cinque minuti di storia proiettati quattro ore in avanti amplificano ogni fluttuazione casuale, e la regressione diventa instabile al punto che oggi prevede saturazione fra trenta minuti, fra cinque minuti la prevede fra sei ore, e così via in un pattern che non serve a nessuno.
La regola pratica empirica è che la finestra storica dovrebbe essere almeno un quarto dell’orizzonte di proiezione. Proiezione a quattro ore implica finestra di almeno un’ora; proiezione a ventiquattro ore implica finestra di almeno sei ore. Più la finestra è lunga rispetto all’orizzonte, più la regressione è stabile e meno reattiva al rumore istantaneo.
Pattern ciclici (false positive garantiti)
L’esempio canonico è il disco di un application server che cresce durante il giorno per via dei log applicativi e viene svuotato di notte dalla log rotation. predict_linear applicato a una finestra catturata in piena mattinata vede una retta che sale e prevede serenamente “pieno entro stasera”, ma la rotazione notturna resetterà tutto e l’alert sarà un falso positivo certo.
Il workaround pragmatico è usare una finestra di almeno ventiquattro ore per qualsiasi metrica con pattern giornaliero, in modo che la regressione veda almeno un ciclo completo di rotazione. La soluzione più solida è passare al forecasting con Holt-Winters o Prophet, che modellano esplicitamente la stagionalità: argomento del terzo articolo della serie.
Soglia statica vs orario lavorativo
“Pieno entro quattro ore” non equivale a “pieno entro quattro ore lavorative”. Un alert predittivo che scatta alle due di notte con un lead time di quattro ore è operativamente inutile se nessuno sta presidiando il sistema fino alle nove del mattino: il risultato è un alert che ha svegliato qualcuno senza fornire una finestra d’azione utile.
Per gestire questo serve splittare il routing: alert predittivo verso un canale low-urgency (Slack del team, email) durante l’orario lavorativo, alert reattivo verso PagerDuty 24/7 come rete di sicurezza. Le recording rule che applicano la predizione solo durante le business hours tramite condizioni come hour() >= 9 and hour() < 18 sono un altro strumento utile per ridurre i falsi positivi notturni senza rinunciare alla copertura reattiva.
Quando Usare Quale: Tabella Decisionale
La teoria è interessante, ma in pratica serve sapere “per questa risorsa specifica, quale alert mi serve davvero?”. La tabella sotto sintetizza dieci risorse comuni e indica quale tipo di alert ha senso in ciascun caso, tenendo conto del time-to-saturation tipico della risorsa e della scala temporale su cui il problema si manifesta. L’obiettivo non è essere esaustivi ma dare un punto di partenza concreto per ragionare sui casi reali.
| Risorsa | Reattiva | Predittiva | Note |
|---|---|---|---|
| CPU run queue | Sì | No | Troppo volatile per regressione lineare |
| Memory / JVM heap | Sì (OOM imminente) | Sì (leak progressivo) | Entrambi, finestre diverse |
| Disk space | Marginale | Sì | Caso d’uso classico |
| Connection pool | Sì | Marginale | Si satura in secondi |
| Certificato TLS | No | Sì | Predittivo per natura |
| Quota API mensile | No | Sì | Capacity planning |
| Kafka consumer lag | Sì | Sì | deriv meglio di predict_linear |
| Thread pool | Sì | Marginale | Comportamento simile al connection pool |
| Log retention | No | Sì | Settimane/mesi |
| Database row count | No | Sì | Orizzonte lungo |
Regola euristica: la versione predittiva ha senso quando il time-to-saturation è nell’ordine di ore o giorni e c’è margine per agire prima dell’impatto utente. Per tutto ciò che si satura in secondi o minuti, la versione reattiva è l’unica scelta sensata. Rendere predittivi gli alert per default è un anti-pattern: ogni alert predittivo va giustificato dal lead time effettivo offerto rispetto alla controparte reattiva.
Conclusione e Prossimi Passi
La distinzione USE/Golden Signals su saturation non è una sottigliezza accademica: cambia operativamente quando e a chi arriva la pagina, ed è la differenza tra una sveglia notturna a servizio già degradato e un ticket diurno aperto con margine d’intervento.
- La distinzione USE/Golden Signals su saturation è esplicitata nei testi originali dei due framework, non è interpretazione personale, e cambia il tipo di domanda a cui gli alert dovrebbero rispondere
predict_linearè lo strumento base per gli alert predittivi in Prometheus, ma ha trappole concrete: crescita non lineare, finestre sbagliate, pattern ciclici, soglie non time-aware- La scelta tra reattiva e predittiva dipende dal time-to-saturation della risorsa, non dal framework di riferimento: entrambi vanno usati quando hanno senso, senza rendere predittivo tutto per default
Nel prossimo articolo della serie si vedrà come gli alert burn-rate applicati agli SLO portano questa logica un livello più in là: non più “quando si satura la risorsa” ma “quando l’error budget della settimana è in esaurimento”. L’articolo successivo esplorerà il forecasting avanzato con Holt-Winters e Prophet per metriche con pattern stagionali, dove
predict_linearsmette di funzionare.
Per chi vuole capire come queste regole si traducono in uno stack di observability concreto, un affondo mirato è un intervento di due settimane che parte proprio dall’alerts.yml esistente e dalle metriche già raccolte: porta un primo miglioramento concreto e lascia la mappa di dove conviene intervenire dopo.
Risorse
Le fonti primarie a cui rimanda questo articolo, più qualche approfondimento utile per scendere nei dettagli che qui sono stati solo accennati.
Definizioni primarie
- Google SRE Book: Monitoring Distributed Systems: il capitolo 6 che introduce i Four Golden Signals
- Brendan Gregg: The USE Method: la definizione canonica di saturation reattiva
- Tom Wilkie: The RED Method: perché RED non include saturation
PromQL e implementazione
- Prometheus:
predict_linear()documentation - Prometheus: Alerting best practices
- Robust Perception blog: esempi pratici e trappole di
predict_linear
Approfondimenti SRE
- Alex Hidalgo, Implementing Service Level Objectives (O’Reilly, 2020)
- Niall Murphy et al., The Site Reliability Workbook (O’Reilly, 2018): capitolo 5 su alerting basato su SLO
Demo repo