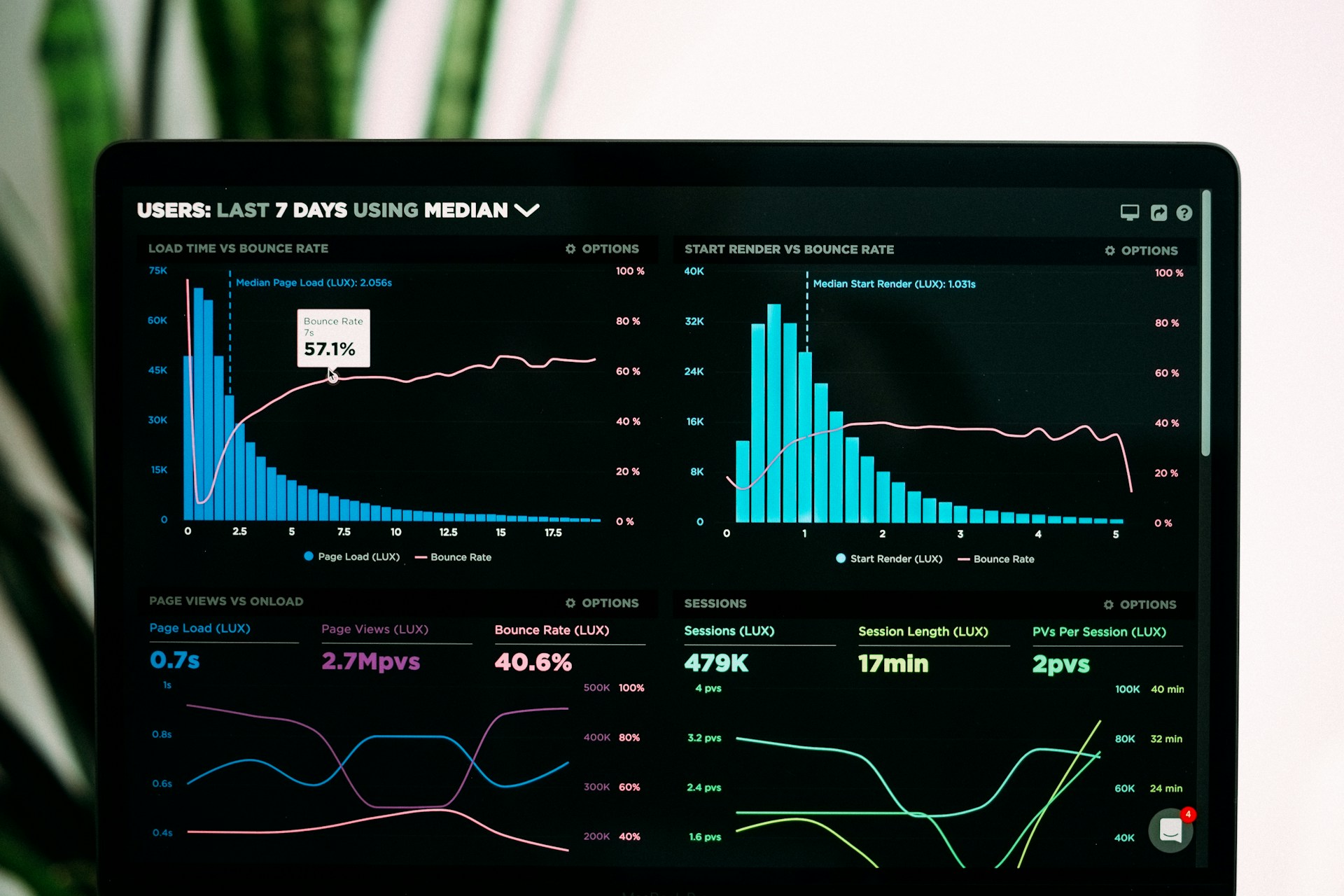
Observability in Distributed Systems: From Monitoring to Understanding
The Exitless Maze: A New Analogy for Observability Imagine you are a brilliant architect, responsible for a huge and intricate building, full of complex systems: heating, ventilation, lighting, security, elevators. You have installed sensors everywhere: every temperature, every pressure, every watt of energy consumed is recorded. Your control dashboards are a profusion of charts and data, every parameter is monitored to perfection, every line is green and reassuring. You know exactly what is happening in every single corner of the building.