Lo Stack LGTM e OpenTelemetry: Osservabilità Completa per i Tuoi Sistemi Distribuiti
Abbiamo esplorato i principi dell’observability e il ruolo fondamentale di OpenTelemetry come standard unificante per la telemetria. OpenTelemetry ci fornisce gli strumenti per generare e raccogliere dati di altissima qualità (metriche, log e trace) in un formato agnostico e coerente. Ma una volta che questi preziosi segnali sono stati raccolti, dove vengono archiviati, interrogati e, soprattutto, visualizzati in modo significativo?
È qui che entra in gioco lo stack LGTM, una potente combinazione di strumenti open source che formano una soluzione di observability completa e integrata, sviluppata e supportata principalmente da Grafana Labs.
LGTM è un acronimo che sta per:
- Loki (per i Log)
- Grafana (per la Grafica e Visualizzazione)
- Tempo (per i Trace)
- Mimir (per le Metriche)
Questo stack è progettato per lavorare in perfetta sinergia con OpenTelemetry, fornendo i backend scalabili e resilienti necessari per immagazzinare e interrogare l’enorme volume di dati di telemetria generato dai moderni sistemi distribuiti. La sua architettura cloud-native lo rende ideale per ambienti dinamici come Kubernetes, offrendo una visione olistica della salute e delle performance delle applicazioni.
Le Componenti Essenziali dello Stack LGTM
Ogni componente di LGTM è specializzato nella gestione di un tipo specifico di segnale di telemetria, ma tutti convergono in Grafana, che funge da interfaccia unificata per l’analisi e la correlazione.
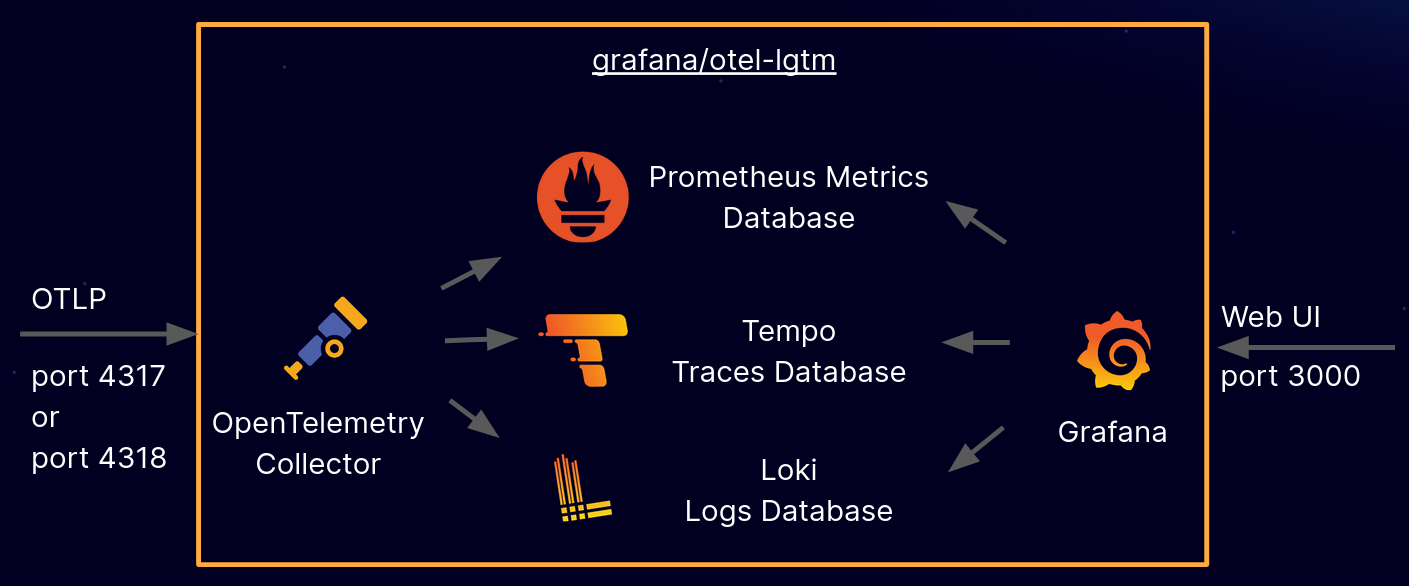
1. Loki: Logging Aggregato, Scalabile e Costo-Efficiente
Loki è un sistema di aggregazione di log ispirato al design di Prometheus, ma ottimizzato per i log. La sua filosofia distintiva è “Non indicizzare il contenuto dei log, bensì solo le etichette.” Questo approccio lo rende estremamente efficiente in termini di storage e costi, specialmente per volumi elevati di dati.
- Principio Operativo: Invece di indicizzare ogni parola o campo all’interno dei log (come fanno i sistemi ELK/Splunk tradizionali), Loki si concentra sull’indicizzazione solo dei metadati (etichette) associati ai log. I log grezzi vengono compressi e archiviati in un object storage a basso costo (es. S3, GCS) o file system locali.
- Flusso Dati: I log vengono inviati a Loki insieme a un set di etichette (es.
app=checkout-service,env=prod,cluster=us-east-1). Quando viene eseguita una query, Loki utilizza prima le etichette per filtrare rapidamente i flussi di log rilevanti, e solo successivamente recupera il contenuto del log grezzo per applicare ulteriori filtri testuali o trasformazioni. - Linguaggio di Query: LogQL. Simile a PromQL, LogQL permette di interrogare i log basandosi sulle etichette e di applicare funzioni di parsing, filtraggio e aggregazione sul contenuto del log.
- Esempio:
{namespace="production", app="web-app"} |= "error" != "connection refused"(cerca errori nei log dell’app web in produzione, escludendo quelli di “connection refused”). - Esempio di aggregazione:
sum(rate({app="my-service"} |= "login failed" [1m])) by (username)(calcola la frequenza di login falliti per username nell’ultimo minuto).
- Esempio:
- Integrazione con OpenTelemetry: L’OpenTelemetry Collector, tramite l’exporter Loki o un
Grafana Agent(che include la funzionalità Promtail), è il ponte ideale per inviare i log generati dalle applicazioni instrumentate con OpenTelemetry a Loki. È fondamentale che i log includano attributi cometrace_idespan_id(tramite le OpenTelemetry Semantic Conventions per i log) per una facile correlazione con Tempo. - Benefici Chiave: Costo-efficienza (permette di gestire volumi di log molto maggiori a costi inferiori), scalabilità orizzontale e operabilità semplificata.
2. Tempo: Tracing ad Alta Scalabilità per Tracce Distribuite
Tempo è il backend di tracing distribuito di Grafana Labs, progettato specificamente per immagazzinare e interrogare un volume elevatissimo di traces con la massima efficienza e costo-efficacia. La sua innovazione risiede nell’essere uno store di trace “senza indice” (trace ID-indexed).
- Principio Operativo: A differenza delle soluzioni tradizionali che indicizzano ogni attributo all’interno di ogni span (generando overhead di storage e complessità), Tempo indicizza solo il
TraceIDe archivia il trace completo in un object storage a basso costo (es. S3, GCS, o altri). - Flusso Dati: I trace (in formato OTLP) vengono inviati all’OpenTelemetry Collector, che a sua volta li inoltra a Tempo. Quando si cerca un trace specifico, si fornisce il
TraceIDe Tempo recupera il trace completo direttamente dallo storage. - Linguaggio di Query: Principalmente ricerca per
TraceID. Con l’introduzione di TraceQL, Tempo supporta query più avanzate basate su attributi, ma la sua vera potenza emerge quando correlato con LogQL (da Loki) o PromQL (da Mimir) attraverso Grafana. La ricerca per TraceID è la modalità più efficiente e costo-efficace, e per questo è fondamentale la correlazione incrociata. - Integrazione con OpenTelemetry: Tempo è nativamente compatibile con OpenTelemetry. L’OpenTelemetry Collector, configurato con l’exporter OTLP, è il meccanismo preferenziale per inviare i trace direttamente a Tempo. Questa è l’integrazione più fluida, dato che OpenTelemetry genera i trace nel formato standard desiderato da Tempo.
- Benefici Chiave: Costo-efficienza (riduzione drastica dei costi di storage per i traces), scalabilità praticamente illimitata e semplicità operativa grazie all’architettura senza indici complessi.
3. Mimir: Scalabilità Illimitata per le Metriche
Mimir è il backend di metriche distribuito di Grafana Labs, progettato per essere una soluzione multi-tenant, altamente scalabile e a lungo termine per le metriche in stile Prometheus. È la risposta alla necessità di gestire petabyte di serie temporali, superando i limiti di un singolo server Prometheus.
- Principio Operativo: Mimir è un database di serie temporali distribuito che accetta metriche in formato Prometheus (via Remote Write) o, più modernamente, direttamente OTLP. Internamente, è un cluster resiliente e scalabile orizzontalmente, utilizzando object storage per la durabilità dei dati a lungo termine e vari livelli di caching per query rapide.
- Flusso Dati: Le metriche generate dalle applicazioni instrumentate con OpenTelemetry vengono inviate all’OpenTelemetry Collector. Il Collector le esporta verso Mimir utilizzando l’exporter
prometheusremotewriteo direttamente l’exporter OTLP, rendendo Mimir il backend unificato per tutte le metriche del sistema distribuito. - Linguaggio di Query: PromQL. Mimir è compatibile al 100% con PromQL, il linguaggio di query standard per Prometheus. Questo significa che qualsiasi dashboard o regola di alerting Prometheus esistente funzionerà direttamente con Mimir, garantendo una transizione senza problemi per gli utenti Prometheus.
- Integrazione con OpenTelemetry: L’OpenTelemetry Collector è il punto di ingestione primario per Mimir. La sua capacità di ricevere metriche OTLP e poi inoltrarle a Mimir in un formato compatibile (OTLP o Prometheus Remote Write) assicura una piena interoperabilità.
- Benefici Chiave: Scalabilità orizzontale illimitata (gestisce carichi di lavoro enormi), resilienza (alta disponibilità e tolleranza ai guasti), multi-tenancy (isolamento sicuro per ambienti condivisi) e storage a lungo termine affidabile.
4. Grafana: Il Cruscotto Unificato per la Correlazione
Grafana è la piattaforma open source di visualizzazione e analisi per eccellenza, ed è la componente centrale di LGTM che unisce tutti i pezzi del puzzle dell’observability. Funziona come un “cruscotto” universale, permettendo di creare dashboard interattive e personalizzabili da varie fonti di dati.
- Ruolo nello Stack LGTM: Grafana si connette a Loki, Mimir (o Prometheus) e Tempo come data source, fornendo un’interfaccia utente unificata per interrogare e visualizzare log, metriche e trace.
- Funzionalità Chiave:
- Dashboarding Avanzato: Creazione di dashboard con una vasta gamma di visualizzazioni (grafici a linee, barre, tabelle, indicatori, etc.).
- Query Editor Intuitivo: Interfacce dedicate per LogQL (Loki), PromQL (Mimir/Prometheus) e TraceQL (Tempo), facilitando la scrittura di query complesse.
- Alerting: Configurazione di regole di allarme sofisticate basate sui dati visualizzati, con notifiche a vari canali (Slack, PagerDuty, email).
- Esplorazione e Correlazione: La funzionalità più potente di Grafana nello stack LGTM è la sua capacità di correlare i tre segnali di telemetria. Dal grafico di una metrica anomala, è possibile fare il drill-down direttamente nei log o nei trace correlati (es. cliccando su un picco di latenza su un grafico, si può essere portati ai trace delle richieste lente o ai log degli errori di quel periodo). Questo è vitale per la root cause analysis in sistemi distribuiti.
- Integrazione con OpenTelemetry: Grafana non interagisce direttamente con OpenTelemetry per la raccolta dati. Il suo ruolo è quello di consumare i dati che OpenTelemetry ha contribuito a generare e che sono stati immagazzinati nei backend di LGTM, offrendo la piattaforma di visualizzazione e analisi.
- Benefici Chiave: Centralizzazione (un’unica UI per tutti i dati di telemetria), flessibilità (supporto per innumerevoli data source), potente correlazione (integrazione nativa tra metriche, log e trace) e una vasta community che fornisce dashboard e plugin pre-costruiti.
LGTM e OpenTelemetry: La Sinergia Perfetta per Sistemi Distribuiti
La vera forza dello stack LGTM emerge quando lo si combina con la standardizzazione offerta da OpenTelemetry. OpenTelemetry si occupa dell’instrumentazione agnostica e della generazione standardizzata dei dati di telemetria, mentre LGTM fornisce i backend scalabili e integrati per immagazzinare, interrogare e visualizzare questi dati. Insieme, formano una soluzione di observability end-to-end completa e altamente efficace.
Flusso dei Dati Nello Stack Integrato:
- Applicazioni/Servizi: I tuoi servizi distribuiti sono instrumentati con gli SDK di OpenTelemetry (o tramite auto-instrumentation). Generano Metriche, Log e Traces in un formato agnostico e standardizzato (OTLP).
- OpenTelemetry Collector: Questi dati vengono inviati all’OpenTelemetry Collector. Il Collector funge da “hub” intermedio cruciale:
- Riceve dati in OTLP da tutte le applicazioni.
- Applica processori (es. batching, filtraggio, arricchimento con attributi di risorsa, campionamento).
- Instrada i dati ai backend appropriati:
- Traces (OTLP) $\rightarrow$ Tempo
- Metrics (OTLP o Prometheus Remote Write) $\rightarrow$ Mimir
- Logs (tramite exporter Loki o Grafana Agent) $\rightarrow$ Loki
- Backend LGTM:
- Tempo immagazzina i traces.
- Mimir immagazzina le metriche.
- Loki immagazzina i log.
- Grafana: Grafana si connette a Tempo, Mimir e Loki come data source. Gli utenti possono costruire dashboard personalizzate, eseguire query sui singoli tipi di dati e, crucialmente, correlare i dati tra di loro, fornendo una visione olistica e contestualizzata del sistema.
Questo workflow integrato è estremamente potente e riduce drasticamente il tempo per identificare e risolvere la causa radice dei problemi (MTTR) in sistemi distribuiti complessi. Dal rilevamento di un’anomalia nelle metriche, al drill-down nel trace correlato e, infine, all’analisi dei log specifici, i team possono navigare rapidamente tra i segnali per comprendere il comportamento del sistema.
Deployment e Considerazioni Operative
Deployare lo stack LGTM in un ambiente di produzione richiede pianificazione, ma i vantaggi in termini di osservabilità sono significativi.
Architettura Tipica in Kubernetes
In un ambiente Kubernetes, lo stack LGTM e OpenTelemetry sono spesso deployati come segue:
- OpenTelemetry SDKs: Integrati direttamente nelle immagini delle applicazioni (come librerie o auto-instrumentation).
- OpenTelemetry Collector:
- Come Sidecar per ogni pod applicativo: raccoglie telemetria specifica del pod con minimo overhead di rete e la invia a un Collector Gateway centrale.
- Come DaemonSet su ogni nodo: raccoglie metriche a livello di nodo e log dal nodo (es.
kubelet,/var/log). - Come Deployment (Gateway): Un’istanza centralizzata che riceve dati da tutti i sidecar/daemonset, applica processori (es. campionamento tail-based, trasformazioni complesse) e instrada i dati a Loki, Tempo e Mimir.
- Loki, Tempo, Mimir: Deployati come cluster scalabili e resilienti. Spesso utilizzano storage S3-compatibile (es. MinIO, AWS S3, Google Cloud Storage) per la loro durabilità e costo-efficienza.
- Grafana: Deployato come un’istanza centrale a cui gli utenti accedono tramite browser.
Sfide e Best Practices
- Scalabilità: Ogni componente LGTM è progettato per scalare orizzontalmente. È cruciale dimensionare correttamente le risorse (CPU, RAM, storage) in base al volume previsto di telemetria.
- Costi dello Storage: Sebbene Loki e Tempo siano intrinsecamente costo-efficienti, il volume complessivo dei dati può comunque essere elevato. Politiche di retention aggressive e sampling intelligente (nel Collector) sono fondamentali per gestire i costi.
- Gestione della Configurazione: Utilizzare strumenti di Infrastructure as Code (IaC) come Helm, Terraform o Pulumi per gestire il deployment e la configurazione di tutti i componenti, garantendo riproducibilità.
- Monitoraggio Interno: È essenziale monitorare la salute e le performance di ogni componente LGTM e del Collector stesso. Tutti espongono metriche Prometheus per la loro osservabilità interna.
- Aggiornamenti: Mantenere i componenti aggiornati per beneficiare delle ultime ottimizzazioni, funzionalità e patch di sicurezza.
Conclusioni: LGTM come Fondamento dell’Observability Moderna
Lo stack LGTM, in perfetta simbiosi con OpenTelemetry, non è solo una collezione di strumenti; è una piattaforma di observability completa, scalabile, costo-efficiente e profondamente integrata. Rappresenta un pilastro fondamentale per le aziende che operano in ambienti cloud-native e con architetture a microservizi, dove la comprensione del comportamento del sistema è diventata una sfida cruciale.
Adottare LGTM significa investire in una strategia di observability che non solo ti permette di “vedere” cosa sta succedendo nei tuoi sistemi, ma di “capire il perché”, accelerando il debugging, migliorando l’affidabilità e guidando l’innovazione. È la dimostrazione di come gli standard open source e l’ingegneria mirata possano affrontare le complessità intrinseche dei moderni sistemi distribuiti, fornendo agli sviluppatori e agli operatori gli strumenti necessari per dominarli e garantire la stabilità e la performance delle loro applicazioni.